How we use Elasticsearch

At Bigcommerce, we’ve recently migrated our search infrastructure from MySQL full-text indices to Elasticsearch.
Running searches using MySQL full-text indices would take a long time on large stores and occasionally cause web requests to time out. Because full-text indices aren’t scalable, we saw instances where searches on stores with 1M products could take 20+ seconds. The queries also put enormous load on our database cluster.
In addition, we found that the accuracy of our MySQL full-text searches were not consistent and users would often see irrelevant search results.
Storing data in Elasticsearch
We chose not to use Elasticsearch as the primary source of truth for our data for several reasons— it is possible for Elasticsearch to lose writes, it doesn’t support transactions, and updates to indexed documents are not always available immediately.
To keep MySQL and Elasticsearch in sync we implemented an observer pattern. The indexing code subscribes to create, update and delete events for all entities that we want to push to Elasticsearch (products, variants, categories, brands) and triggers an async jobs to index the data.
This pattern allows us to completely decouple the indexing code from our database models. The async job is simply a Resque job running the code responsible for indexing.
Retrieving the data
When a customer searches a store’s catalog, our Elasticsearch cluster is queried for matching product IDs. These IDs are then used to retrieve full records from MySQL, our primary source of truth. MySQL may not be the best for full-text searching but it works very well when it comes to retrieving records by their primary keys. Combining Elasticsearch with MySQL for search is a good compromise for getting relevant, fast and accurate results.
Since we were not using Elasticsearch as the primary source of truth, we decided only to store properties that would be useful for searches.
In Elasticsearch every shard is refreshed automatically once every second which means that it supports near real-time accuracy. Document changes are not visible to search immediately, but will become visible within one second.
Changing Elasticsearch Schema
Making schema changes in Elasticsearch can be problematic— data is not reindexed or analyzed when the when the schema is changed.
You have to first change the mapping (Elasticsearch DDL) and then reindex the documents belonging to that mapping. In some cases, it’s not even possible to change the mapping of a field (e.g., when changing a flat object into a nested object).
We needed the ability to change schema and reindex data without any downtime in case we wanted to make modifications to the index. When making incompatible schema changes, you have two options: delete the current index and reindex it or create a new index and reindex into it.
This process is relatively fast when you only have a few hundred records, but if you’re dealing with hundred of thousands of records it can take hours, during which search would be missing data.
To avoid this, we decided to reindex the data into a secondary index with the new schema while reading the data from the primary index with the old schema. We also have to deal with any modifications that happen during the reindexing process. Any changes made to records after they have been already reindexed would not be reflected in the new index since we’re still using the old index for all CRUD operations. To avoid that, we decided to dual write the data into two indices simultaneously during reindexing to ensure that both indices have the correct data while still reading from the primary one.
Once the reindexing process has been completed we need to point the codebase to the secondary index. Since there is no command to rename an index in the Elasticsearch API, the recommended way of renaming an index is to create an alias. An alias sits on top of an index and you point your requests to the alias instead of to the index directly. This gives you an extra layer of abstraction with the flexibility of quickly renaming your index on the fly.
After the index schema has been changed and the reindexing process has has been completed, we simply change the alias to point to the new index by making an HTTP request to delete the old alias and create the new alias. This allows us to change which index the codebase is using without suffering any downtime.
Our Config
Cluster: 480 shards, 4 masters, 6 data nodes across two DCs
Size of our cluster: 500GB
- Records stored: 250,000,000
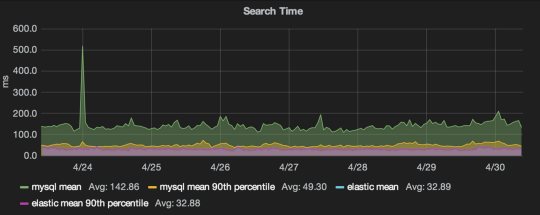
50/50 split MySQL vs Elasticsearch, MySQL was having big trouble when there was a spike whereas Elasticsearch was able to handle it without any problems.
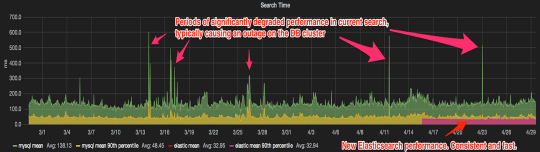
Historical data of MySQL performance, very volatile, whereas Elasticsearch is stable and nearly constant.