Re-Platforming Data @BigCommerce: five second latency on Petabytes of data
Many analysts are hailing Data as the new oil. However, contrary to what they're saying, oil is a depleting resource. Data on the other hand, is an expanding resource.




Many analysts are hailing Data as the new oil. However, contrary to what they're saying, oil is a depleting resource. Data on the other hand, is an expanding resource. At best, Data can be compared to crude oil, in that both are buried way beneath and their enormous value can only be realized by extracting and processing them. The ability to derive actionable insights in real time on massive volumes of ever increasing data is a key differentiator as businesses compete in this era of digital transformation.
BigCommerce offers a comprehensive set of Analytics Reports for Merchants to analyze their business across all key metrics.
Legacy Data platform at BigCommerce
The legacy Data platform at BigCommerce consisted of some 40-odd Hadoop Mapreduce jobs that were triggered using cron jobs. It took about 6 hours before merchants could see their analytics data. Any job failure often required manual restart of the jobs resulting in an increased lag. Adding new functionality was extremely difficult.
Data at BigCommerce powers merchant analytics, as well as BigCommerce’s own marketing and accounting needs. Data was being served through two independent systems, resulting in redundant and siloed data. It required a separate set of ETLs and Data pipelines, adding cost and complexity.
Need for Real Time Analytics
The actionable value of a business event goes down drastically with time after an event is generated. The sooner a business event becomes actionable through data, the higher its value.
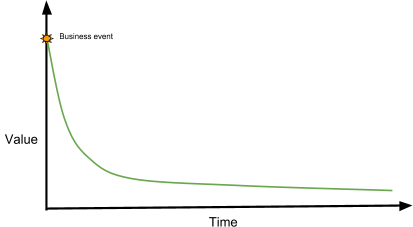
- Conversions by origin: Knowing realtime shopper conversions by sources such as Search, Social, Campaign, Direct, Referrer, etc, allows merchants to act in real time and boost conversion. Merchants can drill further and analyze by search (google, bing,), social (fb, instagram), etc..
- Purchase funnel: Enables merchants to view purchase funnel in real time and take actions if visitors are not viewing products or not adding products to cart in real time.
- Product abandonment: For a time sensitive events, knowing which products are being abandoned in real time enables merchants to fix any product related issues and boost sales.
- Advertisement: Improve effectiveness of campaigns by bidding for keywords, running ads on social channels based on real-time data.
Blaze: The new real-time unified Data platform
At BigCommerce, we process over 800 million events every day. Tens of millions of shoppers shop every day on our platform, generating hundreds of millions of clicks, visits, views, orders, carts, checkout and other events per day. We set out to build a new cloud Data platform which is scalable, multi-tenant, realtime, secure and built on an open source stack. For merchant-side analytics, we set three simple business goals :
- Reduce the data latency from 6 hours to near real time.
- Sub-second response time for analytics reports
- Improved data quality
On the technical architecture side, we embraced the following distributed data design principles:
- Fault tolerant: If any one of the components or an entire system were to fail, it should not impact data processing.
- Redundancy: Store, Manage and Orchestrate redundant copies of data in the situation a system/component that is hosting data fails
- Replay: If the downstream system encounters an issue, system should be able to replay events
- Idempotent: Operations can be retried or replayed without the fear of processing the data multiple times or causing unwanted side effects (at least once processing)
- Scalable: Real time traffic vary from time to time. System should be able to scale up or down as needed without re-architecture, re-deploy etc.
To accomplish the above goals, we incorporated the following modern data approaches :
- Stream processing
- Massively-scalable low-latency data store
- Infrastructure as code
For stream processing, we used Kafka streams. Kafka streams is a lightweight library that processes events one at a time with very low latency. There is no need for a stream processing framework and cluster manager.
For Datastore, we chose HBase, as it provides very high write throughput because of LSM (Log Structured Merge) based write mechanism where files are written sequentially in memory and copied on disk. A separate process (compaction) takes care of merging them in background. A typical RDBMS cannot consume a massive amount of events because of the requirement to write directly into scattered data files on the disk.
To achieve sub-second response for analytics reports, we pre-aggregate data. In the eCommerce domain, aggregates are not simple immutable time series rollups. For example, an order that was placed a week ago can be cancelled or edited. This impacts hourly, daily, weekly, monthly and year-to-date aggregates across all metrics. Our aggregation process determines the impact of changed data, and aggregates affected metrics in a scalable and efficient way. This greatly reduced our compute resources as well as compute time. Data is made available through RESTful API for front end and other systems of our platform.
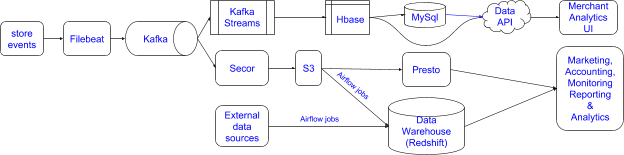
We came up with a json schema to describe events. Events are generated in store front and sent to Kafka using Filebeat.
Our tech stack consists of :
- Apache Kafka: Horizontally-scalable, fault-tolerant and fast eventing bus.
- Apache Kafka Streams: Elastic, scalable, fault-tolerant stream processing service.
- Apache HBase: Distributed, scalable big data store useful for random, realtime read/write access to Big Data.
- MySQL: Performant and highly available cloud-hosted MySQL relational database for aggregated data.
- Puppet and Terraform: Allows management, deployment and automation of infrastructure.
- Apache Airflow: Manages orchestration of ETL jobs.
- Presto: Distributed SQL query engine for running analytical queries against massive datasets.
- Redshift Data Warehouse: Managed data warehouse service in cloud.
Infrastructure as code :
Data platform is fully managed through terraform and puppet. Terraform is an infrastructure automation tool used for managing resources in cloud. Desired state of resources are expressed using Terraform configuration. We use Puppet to install and configure software inside cloud VM instances.
Monitoring, Logging and Alerting :
Any time we deal with real time data processing, monitoring and alerting is critical. We use a host of monitoring and alerting tools such as Kibana, Grafana, Sentry, CloudWatch, etc. We log various event metrics on a scheduled frequency and alert if those metrics fall outside our upper and lower bound thresholds. Here are some sample monitoring charts:

Migrating historical data:
We wanted to transition from legacy data platform to new data platform without introducing any down time, since our merchants heavily use analytics throughout the day. We came up with a cutoff time for copying over large sets of historical data and for the new data, we rewound kafka offsets to re-process few days of data preceding the cutoff time. Along the way, we also corrected historical data inaccuracies.
Results :
We rolled out Blaze to all merchants in November 2018. The new pipeline has been performing extremely well without any hiccups including the period of two major events for ecommerce domain: Black Friday and Cyber Monday. The new data infrastructure has been very stable and reliable. Here is how we measured against our set business goals :
- Latency: We achieved data latency of less than 5 seconds. The legacy data latency was 6+ hours.
- Response time: Our response time from Data APIs is in the range of 500 milliseconds.
- Data quality: We saw drop in data quality issues reported by merchants and data accuracy has improved considerably.
As we retire redundant infrastructure, we will see cost savings to the tune of 30% to 40%.
Some issues we ran into :
Large visit counts due to bots: We saw 2x to 3x visit counts in Blaze compared to legacy data pipeline. This massively impacted conversion ratios. It turns out that Bots that do not enable java scripts were firing bot visits. We then switched to a Javascript mechanism to fire visit events. This brought the visit count down to normal range.
Order time zone mismatch: BigCommerce serves merchants in 120+ countries. When a merchant changes their timezone between order creation and order update, the historical aggregates would get bucketed incorrectly. We ended up updating the event schema to include order creation time zone offset, cleared previous aggregates and recomputed all aggregates.
What’s next :
We now have a foundational Data platform and we are just getting started! We are building deeper insights to empower merchants to discover hidden sales opportunities and grow their business. We are also building machine learning models for prediction and recommendations to enhance merchant and shopper experiences.