How We Swapped Out Our Service Mesh, without Anyone Noticing
The future of routing at BigCommerce is wide open.


At BigCommerce Product & Engineering, we serve merchants across the globe, and have been working to provide them the fastest, most efficient infrastructure we can provide. This has manifested itself in numerous ways over the years, but over the past year, we noticed that our service mesh — then, Linkerd, had become a bottleneck for expansion.
Data Article: Use of Kafka and Kafka Streams
History of Linkerd at BigCommerce
At BigCommerce, we run a service-oriented architecture, primarily consisting of VM instances and a fleet of Nomad servers and clients for our hundreds of services. We heavily use Consul for identity networking, providing us a reliable service discovery system, and prior to this year had been relying on Linkerd1 for our service mesh.
We ran Linkerd on our nomad-client nodes and on our VMs, acting as a node-local proxy for applications and services to talk through, either via HTTP1 or gRPC traffic. Combined with Consul, this allowed us to seamlessly connect applications and infrastructure across our fleet — whether running in containers or directly on VM instances — without hassle or extra configuration.
In order to prevent our engineers from manually wiring up the mesh, we utilized a Consul “namer” in Linkerd to allow it to auto-discover services. Linkerd allows you to specify a router with ingress ports and a “namer.” That namer is used by the router to interpret and direct that traffic. For HTTP1 traffic, engineers point their services to [𝚌𝚘𝚗𝚜𝚞𝚕-𝚗𝚊𝚖𝚎-𝚘𝚏-𝚜𝚎𝚛𝚟𝚒𝚌𝚎].𝚕𝚒𝚗𝚔𝚎𝚛𝚍:𝟺𝟺00. This automatically routes the traffic to that service without any additional information.
For gRPC traffic, it was even simpler: using the “path” header present in gRPC requests, we could just have engineers point to 𝚕𝚒𝚗𝚔𝚎𝚛𝚍:𝟺𝟺0𝟸, and Linkerd would route traffic dynamically via a Consul interpreter on the router:
identifier:
kind: io.l5d.header.path
segments: 1
interpreter:
kind: io.l5d.consul.interpreter
namespace: h2
We had a small service named “meshroute” that would watch for Consul services as they came online. Meshroute looked for tags on those services and wrote dtabs (delegation tables, powered by Finagle, which Linkerd uses for its routing logic) to a K/V store in Consul. This produced routes like the following:
/svc/bigcommerce.catalog.products.assignments.ProductAssignments => /#/io.l5d.consul/integ-us-central4/product-assignments;
From which Linkerd would determine how to route paths. The service would declare which gRPC services it served in a configuration file used by our deployment tooling, and everything would “just work” without any more steps required by engineers.
It was great. Until, it wasn’t.
Limitations of Linkerd1
Linkerd served us well for years at BigCommerce, but we started hitting some scaling issues with it as our infrastructure matured:
- Noisy neighbor problems - Since in our configuration Linkerd1 runs on a VM host, not as a sidecar to a container, it means that all the containers on a Nomad instance share the same Linkerd process. If one service burst traffic over a sustained period of time, this would consume available connections and CPU, and eventually slow down other services on that host. This caused performance issues across the fleet when we would get burst traffic. There was no mechanism for us to guarantee system resources for a particular service or traffic path.
- Uneven distribution of traffic between services - Our container scheduler (Nomad) performs “bin-packing” which is a process by which services are scheduled densely onto hosts. With a single ingress and egress Linkerd instance running per VM host, it meant that Linkerd did not have visibility into the complete number of instances of a running service. This meant if there were several instances of a containerized service running on the same VM host, they would receive less traffic, as to the egress Linkerd it could only see the single ingress Linkerd instance.
- Lack of L7 network configuration - L7 (or Layer 7) configuration is essentially the configuration layer of application traffic routing. Linkerd1 allows some configuration through Finagle delegation tables, but this is limited and doesn’t have the flexibility other systems (like, say, Istio) do.
- Linkerd1 to Linkerd2 - Buoyant, the company behind Linkerd, rewrote Linkerd to Linkerd2, which was a faster, more flexible iteration, with one big caveat: it required Kubernetes. Our container scheduler is Nomad, and the deep integration between Linkerd2 and K8S meant that Linkerd2 was not a viable option for us.
- Moving internationally - We wanted to move our infrastructure to an isolated infrastructure per-region, while still allowing services to route to “global” services that operated in a single region (such as our identity and access management services, which needed to operate singularly across geographies). This presented itself with complicated routing challenges, which Linkerd1 did not support.
It was clear we needed to find a replacement mesh. And we needed to yank the carpet out from under our service-oriented architecture without anyone noticing.
The Consul Connection
At the time, HashiCorp had just released a new mesh in the form of Consul Connect; this fit our use cases well, allowing dynamic L7 control via Consul configuration entries, natively working in our already existent HashiCorp stack, and offering faster performance and resource isolation by using Envoy Proxy as a sidecar instead of our Linkerd1’s host-based deployment.
We were able to get it running fairly quickly — essentially having services declare their “upstreams” via our configuration file, like so:
networking:
upstreams:
http1:
- catalog:7100
grpc:
- storefront-styling:8100
- storefront-rendering:8101
These would establish local ports in the source service bound to a socket, which then the Envoy sidecar would “route” traffic to the destination service at the provided consul name appropriately:
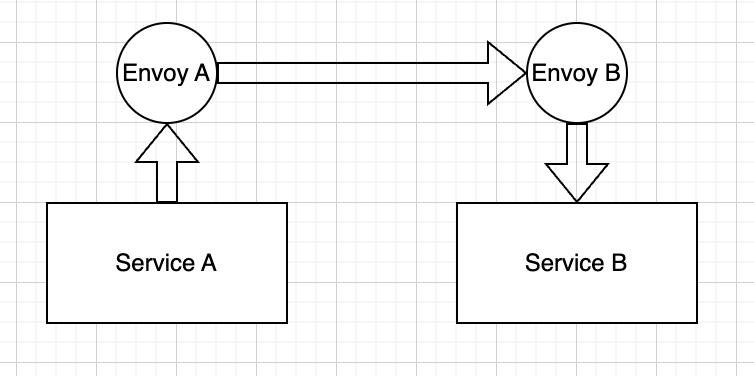
These ports are local to the application; they only needed to be unique per app, so we never had to worry about centralized routing configuration or port conflicts. Secondly, this gave us the immediate ability to generate topology graphs for our SOA straight from these network definitions.
Unlike Linkerd’s “pull” model for Consul routing lookups, Consul Connect utilizes Envoy’s XDS (discovery) API to push routing (via what it calls clusters for each mapped container instance) into the Envoy sidecar itself. This means the Envoy sidecar only has to know about traffic destinations that are explicitly declared, keeping its security profile low and performance light. It also removed the need for our “meshroute” service, as now Consul handled all of the path mappings internally.
We then pushed Consul service-defaults entries during deployments to automatically update service L7 configuration. This allowed us to dynamically alter service configuration on deployments, without any out-of-band configuration.
Finally, application owners just needed to change their target host and port to 𝟷𝟸𝟽.0.0.𝟷:𝚞𝚙𝚜𝚝𝚛𝚎𝚊𝚖-𝚙𝚘𝚛𝚝-𝚑𝚎𝚛𝚎 to shift to Envoy from Linkerd automatically. This would then direct their requests into the Envoy path, bypassing Linkerd entirely.
Risk Management
Sounds simple, right?
Well, the service mesh internal to the BigCommerce platform is sometimes serving hundreds of thousands of internal requests per second, carrying all requests of all different types, sizes, and protocols. Just on/off flipping traffic to a brand new mesh wasn’t going to work for us.
We primarily use 3 main languages at BigCommerce — Ruby, Scala, and PHP - and have common client libraries that are utilized for in-application client generation across all of them. These clients configure their target hosts centrally and typically via environment variable configuration. So we adjusted our client libraries to allow us to percentage-rollout between service meshes dynamically.
Related Article: 6 Tips for Scala Adoption
For example, we utilize gruf for gRPC at BigCommerce, and we wrote an open-sourced gruf-balancer, which allowed for percentage balancing egress calls from a service via a provided configuration. This — and similar approaches in other languages — allowed us to dynamically shift traffic on a percentage basis across the platform from Linkerd to Consul Connect (Envoy). We could toggle that via environment variables, or in some higher-risk cases, via hot configuration entries triggered by Consul k/v updates without service restarts.
Furthermore, Nomad automatically injects upstream addresses as environment variables into containers, so we were able to just have internal libraries automatically lookup the address from env, as opposed to manually mapping it ourselves:
NOMAD_UPSTREAM_IP_PRODUCTS_SERVICE=127.0.0.1
NOMAD_UPSTREAM_PORT_PRODUCTS_SERVICE=8000
NOMAD_UPSTREAM_ADDR_PRODUCTS_SERVICE=127.0.0.1:8000
…where the name matched the name of the Consul service. Our libraries then used standard naming conventions for percentage variables, allowing us to standardize rollouts across the platform. Like moving a slider up and down on a soundboard, we were able to ease ourselves into our new service mesh at a rate we were comfortable with.
Monitoring
Envoy via consul connect emits thousands of Prometheus metrics per-sidecar, which was perfect for us as we are heavy users of Prometheus at BigCommerce. However, in order to not overwhelm our Prometheus clusters with the high cardinality of metrics coming from Envoy, we added filters and allowlisted only necessary metrics from Envoy that we wanted to use.
This allowed us to create insightful Grafana boards that gave us high levels of visibility into traffic patterns on our platform:
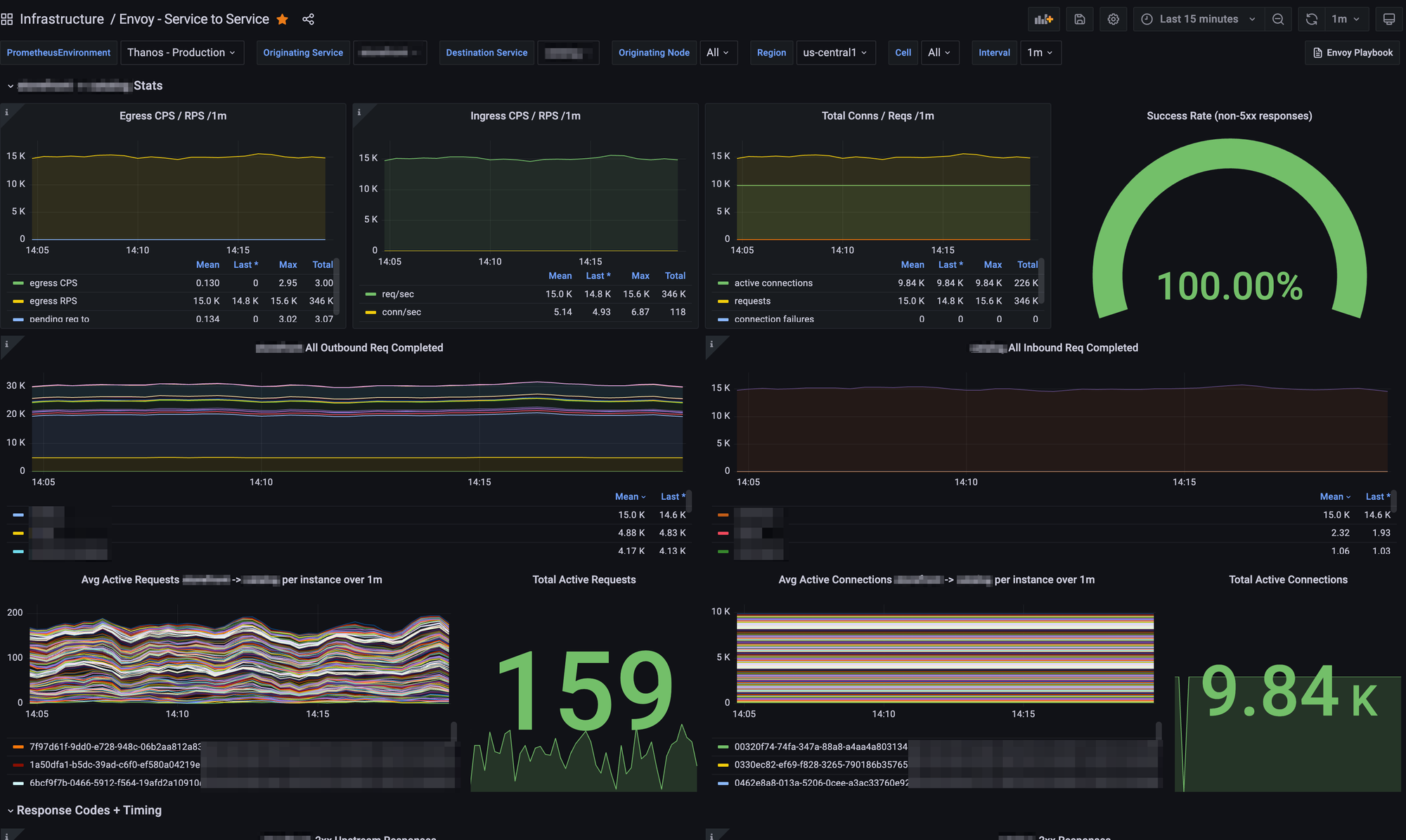
We could easily, at any point, get full visibility into internal traffic patterns and metrics between any two services.
This immediately helped service owners...
- feel confident and know exactly how their traffic was flowing across their services as we switched over to Consul Connect.
- get fine-grained visibility into problems that might occur from improper sidecar sizing, such as pending request queueing, concurrency issues, or connection timeouts.
- monitor upstream response times from various sources to understand bottlenecks.
It also gave us a ton of metrics to create proactive alerting; we now had the ability to create Prometheus-backed alerts on TLS connection errors, unhealthy upstreams, XDS failures, and undersized Envoy sidecars. Diagnosing problems in the mesh became tremendously easier to do.
Finishing the Job
Over the course of a few months, we strategically shifted our inter-service network traffic from Linkerd to Envoy with minimal-to-no impact. The iterative rollout allowed us to tweak configuration settings (such as sidecar CPU per service, request timeouts, concurrency, etc.) as we went, monitoring and adjusting as needed.
Today, we stand nearly entirely shifted over, with only a small amount of infrequently used legacy traffic patterns left to tidy up.
The impact to both service teams and our merchants was zero.
For most service teams, switching was simply the matter of tuning environment variables and ramping up as they were comfortable, most in a matter of hours. Due to our work with observability metrics, they had full insight into the directional flow of their traffic as well, getting detailed analysis of how their requests were performing with Envoy.
Our overall service mesh stability is notably better with the upgrade, and the noisy neighbor problems of the past have entirely disappeared. We saw more consistent spread of traffic across nodes as well with Envoy, having significant improvements to prevent overload on single hosts or containers.
We’re happy users of Consul Connect, now that we’ve switched over to it. The insight we get to traffic on our platform is leagues further along than years ago, and we’ve been able to use its configuration entries to do things like blue/green deployments, dynamic traffic splitting, traffic mirroring, running prototype versions of services in production dark for testing, routing traffic dynamically internationally, and all without any impact to merchants or our larger infrastructure.
The future of routing at BigCommerce is wide open.
Thanks for reading this post, and happy meshing! If you have any questions for me, contact me on LinkedIn.