Use of Kafka and Kafka Streams at BigCommerce
Data streaming is at the heart of BigCommerce’s real-time Data platform.





Contributing authors: Mahendra Kumar, Aristatle Subramaniam, Divya Sanghvi, Eugene Kuzmenko, Jun Bai, Krishna Teja Are, Maria Mathew, Nandakishore Arvapaly, Roman Malyavchik, Santhosh Saminathan, and Yadong Chen
BigCommerce is a leading modern SaaS eCommerce platform serving tens of thousands of merchants in 150+ countries. BigCommerce is an Open Saas eCommerce platform that enables merchants to create commerce solutions for B2B, B2C, Multi-Storefront, Omnichannel, Headless, and International.
Data streaming is at the heart of BigCommerce’s real-time Data platform. BigCommerce’s Data platform ingests over 1.6 billion messages each day consisting of eCommerce events such as visits, product page views, add to cart, checkouts, orders, etc. These events are processed and aggregated across multiple dimensions of Online Analytical Processing (OLAP) cubes for a rich set of Analytics reports and actionable insights for merchants. These events enable us to build real-time product recommendations for shoppers using machine learning models. These events are also used for server-side transmission to merchant-enabled channels such as Meta (formally Facebook) using Meta Conversion API. Raw events from Confluent Kafka are stored in GCP BigQuery using the Confluent sink connector for use as a data lake, ad hoc analysis, platform-wide reporting, etc.
Kafka and Kafka streams link events from multiple input sources and their destination use-cases while keeping them decoupled. Here are a few use cases of how BigCommerce is using Confluent cloud and Kafka streaming:
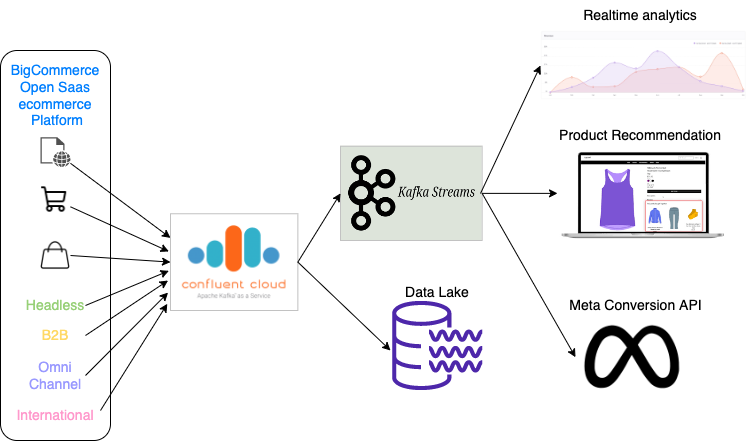
Real-time Analytics and Insights for Merchants
BigCommerce offers a comprehensive set of real-time analytics and actionable insights for eCommerce merchants to grow their businesses. Scalability, near-zero latency, reliability, availability, and fault tolerance are key requirements for BigCommerce's Data platform.

BigCommerce adopted fully managed Confluent Kafka as a core part of its Data platform. Kafka handles scaling of massive event volumes and throughput during peak seasons such as CyberWeek without having to plan, provision and re-size clusters, allowing the BigCommerce Data team to focus on building Data solutions instead of managing and monitoring Kafka clusters. Steady-state Kafka write throughput is about 22mbps and read throughput is about 60mpbs and growing. It goes up substantially during retail seasons such as CyberWeek. Kafka Streams is used for consuming, de-duping, parsing, transforming, bot filtering lookup, and slicing & dicing data. Kafka Streams provides a lightweight library that processes events one at a time with very low latency without the need for a stream processing framework and cluster manager. Kafka Streams is used for preparing data for OLAP style cubes and keeping them updated in real-time.
Server-side Event Transmission for Meta’s Conversion APIs
BigCommerce’s integration with Meta’s Conversion API helps merchants effectively run advertising campaigns on customer audiences. Conversion API creates a direct and reliable connection between merchant store and Meta and helps power ad-personalization, optimization, and measurement on Meta.
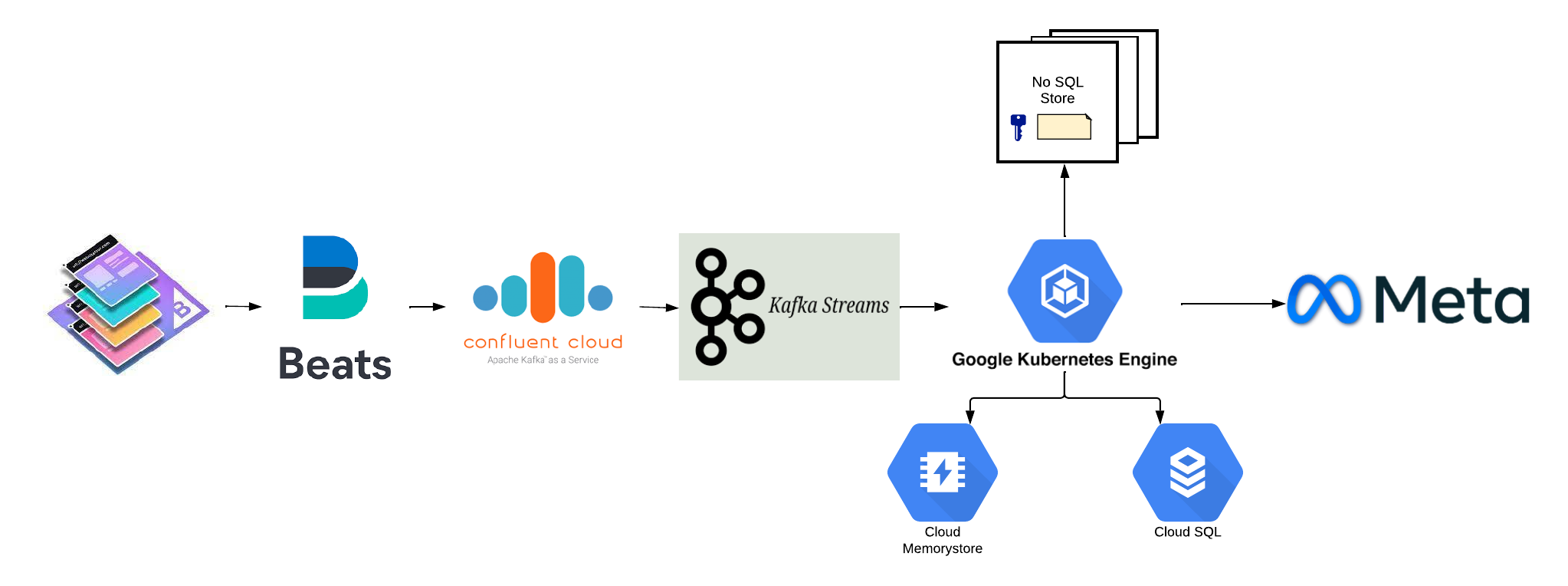
Server-side commerce events such as visits, product page views, add to cart, orders, etc., are generated and transmitted to Meta using FileBeats, Kafka, Kafka Stream and GKE. Events sent through Conversions API are less impacted by browser loading errors and connectivity issues. Kafka Streams is used for deduping, lookup, transformation, and API calls to Meta’s Conversion API.
Data Lake
BigCommerce uses the Confluent Connector to create a Data Lake to store all the raw events.
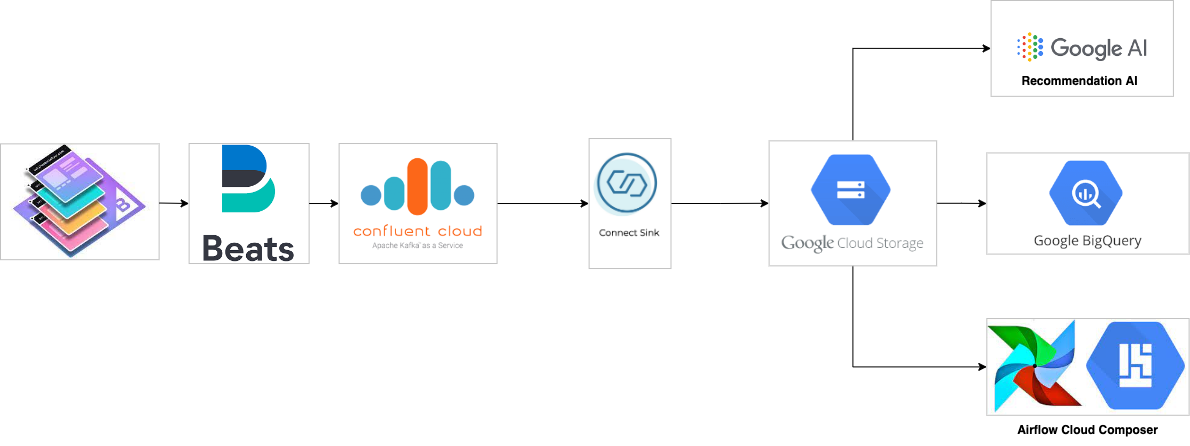
We use the GCS Sink Connector to store and archive our raw events. BigCommerce uses the raw events mainly for batch processing and running ad-hoc queries. Another important reason we use raw data is to train the machine learning model that is used for personalizing product recommendations. The machine learning model requires us to provide historical data for at least 3 months of raw events. Once the connector pushes the data into Cloud Storage, we use Google BigQuery as an External Table so we can run the ad-hoc queries. We also use the raw events for processing our batch jobs on Airflow Cloud Composer to do our batch processing which reads the data from the GCS (published by sink connector).
Bot Filter Exploration Using KsqlDB
Bots and crawlers can skew analytics data such as conversion ratio, purchase funnel, etc. The volume of bot traffic has been on the rise contributing to as much as 40% of product page view and shopper visit events.
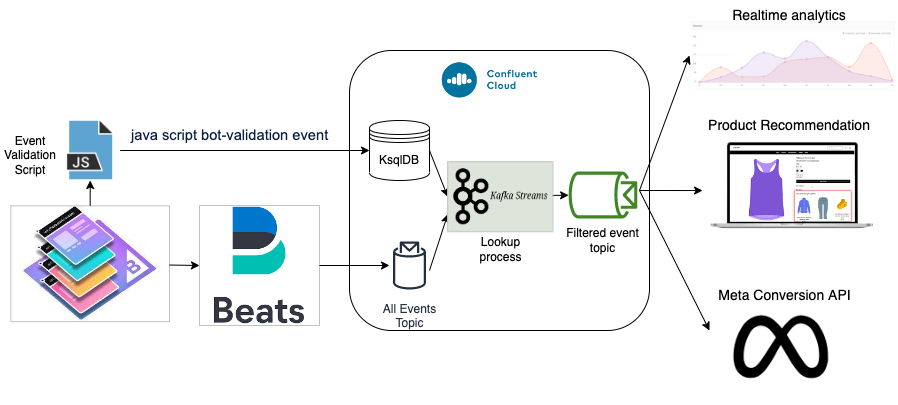
To filter bots, BigCommerce Data platform triggers a JavaScript bot-validation event which is sent to a bot-filtering service. The non-bot validation events are stored in KsqlDB table created through a topic in Confluent Cloud. All eCommerce server-side events such as visits, product page views, carts, orders, etc., are ingested into an ‘all events’ Kafka topic. These incoming events are looked up against the validated non-bot data in KsqlDB and resultant filtered events are sent to a ‘filtered event’ topic. This resultant ‘filtered event’ topic contains non-bot events that are consumed by various downstream consumers. Having a single place to filter bots and creating a new topic makes the data pipeline cost efficient and performant. Although we successfully achieved filtering of bot events, the latency lookup from KsqlDB is around 60ms to 80ms which is high for our use-case, hence, we are currently using Redis to store Javascript event, where the latencies are a few ms.
Machine Learning Based Real-time Personalized Product Recommendation Proof of Concept
BigCommerce's personalization shows recommended products to shoppers using real-time machine learning techniques through Google's Recommendation AI.

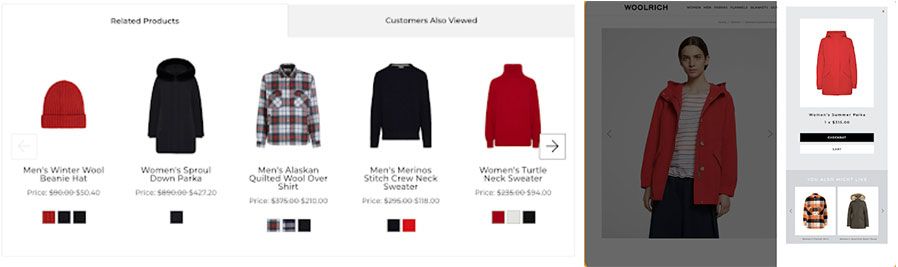
Real-time shopper events such as product page views and orders are ingested into Confluent Kafka, consumed by Kafka streams, and are used for building machine learning models. Kafka stream is used for parsing, de-duping, and interfacing with Google Recommendation AI to send personalized events. The constant real-time feedback loop keeps the model updated to the second. The entire pipeline is running with sub-second latency. The initial models used are 'Others you may like' and 'Frequently bought together.’ Here are the results of A/B testing with one of BigCommerce's merchants:
- 28% lift in Click-Through Rate for “Related Products” section
- 269% lift in revenue among shoppers who engaged with related products
- 3.82% lift in overall revenue
- 7.4% Increase in Conversion Rate from Visit to Orders with 2 or more items
- 2.65% increase in AOV
Meet More BigCommerce Engineers
- The Mobile Team Discusses How Developer Conferences Deliver Inspiration and Innovation
- Overcoming Adversity: Meet Our Software Engineer, Kevin Carr
- International Women’s Day Spotlight: Meet Tulasi Anand
- Women’s History Month Feature: Meet Judith Dietz
- Women’s History Month Showcase: Meet Tharaa Elmorssi